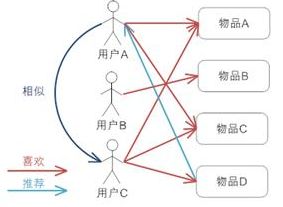
DSSM模型详解
1. DSSM模型原理和结构
模型原理:
通过搜索引擎里Query和Document的海量的点击曝光日志,用DNN深度网络把Query和Document表达为低维语义向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义Embedding向量。
模型结构

其中Q代表Query信息,D表示Document信息。
(1)Term Vector:表示文本的Embedding向量;
(2)Word Hashing:为解决Term Vector太大问题,对bag-of-word向量降维;
(3)Multi-layer nonlinear projection:表示深度学习网络的隐层;
(4)Semantic feature :表示Query和Document 最终的Embedding向量;
(5)Relevance measured by cosine similarity:表示计算Query与Document之间的余弦相似度
(6)Posterior probability computed by softmax:表示通过Softmax 函数把Query 与正样本Document的语义相似性转化为一个后验概率
2. DSSM模型在推荐召回中的应用
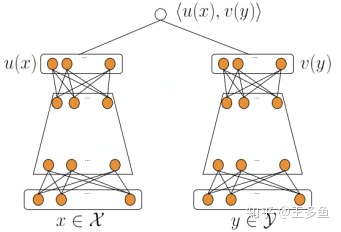
DSSM 模型的最大特点就是 Query 和 Document 是两个独立的子网络,后来这一特色被移植到推荐算法的召回环节,即对用户端(User)和物品端(Item)分别构建独立的子网络塔式结构。该方式对工业界十分友好,两个子网络产生的 Embedding 向量可以独自获取及缓存。目前工业界流行的 DSSM 双塔网络结构所图。
双塔模型两侧分别对(用户,上下文)和(物品)进行建模,并在最后一层计算二者的内积。
其中:
- $x$ 为(用户,上下文)的特征,$y$ 为(物品)的特征;
- $u(x)$ 表示(用户,上下文)最终的 Embedding 向量表示,$v(y)$ 表示(物品)最终的 Embedding 向量表示;
- <$u(x), v(y)$> 表示(用户,上下文)和(物品)的余弦相似度。
候选集合召回
当模型训练完成时,物品的 Embedding 是可以保存成词表的,线上应用的时候只需要查找对应的 Embedding 即可。因此线上只需要计算 (用户,上下文) 一侧的 Embedding,基于 Annoy 或 Faiss 技术索引得到用户偏好的候选集。