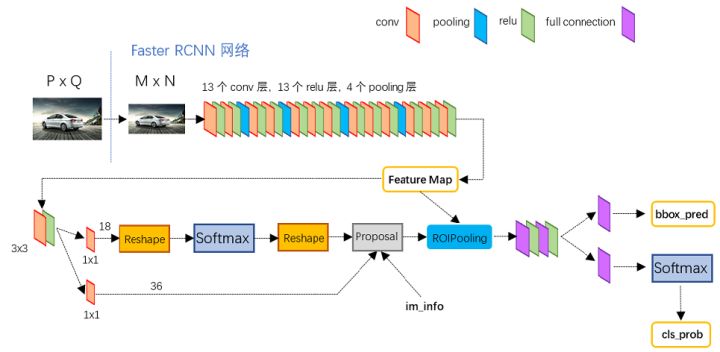
faster rcnn相关详解
1. cascade rcnn
1.1 mismatch问题:
在R-CNN中用到IoU阈值的有两个地方,分别是Training时Positive与Negative判定,和Inference时计算mAP。
- training阶段,RPN网络提出了2000左右的proposals,这些proposals被送入到Fast R-CNN结构中,在Fast R-CNN结构中,首先计算每个proposal和gt之间的iou,通过人为的设定一个IoU阈值(通常为0.5),把这些Proposals分为正样本(前景)和负样本(背景),并对这些正负样本采样,使得他们之间的比例尽量满足(1:3,二者总数量通常为128),之后这些proposals(128个)被送入到Roi Pooling,最后进行类别分类和box回归。
- inference阶段,RPN网络提出了300左右的proposals,这些proposals被送入到Fast R-CNN结构中,和training阶段不同的是,inference阶段没有办法对这些proposals采样(inference阶段肯定不知道gt的,也就没法计算iou),所以他们直接进入Roi Pooling,之后进行类别分类和box回归
一般proposals与iou阈值成反比,如图所示

那么,分析训练和预测阶段的异同:
- 在training阶段,由于我们知道gt,所以可以很自然的把与gt的iou大于threshold(0.5)的Proposals作为正样本,这些正样本参与之后的bbox回归学习。
- 在inference阶段,由于我们不知道gt,所以只能把所有的proposal都当做正样本,让后面的bbox回归器回归坐标。
我们可以明显的看到training阶段和inference阶段,bbox回归器的输入分布是不一样的,training阶段的输入proposals质量更高(被采样过,IoU>threshold),inference阶段的输入proposals质量相对较差(没有被采样过,可能包括很多IoU<threshold的),这就是论文中提到mismatch问题,这个问题是固有存在的,通常threshold取0.5时,mismatch问题还不会很严重。
1.2 分析解决方法
为了获得更高精度,往往通过提升iou来做到,那么会引起的问题:
- 过拟合问题。提高了IoU阈值,满足这个阈值条件的proposals必然比之前少了,容易导致过拟合。
更严重的mismatch问题。前面我们说到,R-CNN结构本身就有这个问题,IoU阈值再提的更高,这个问题就更加严重。
通常情况下
- 只有proposal自身的阈值和训练器训练用的阈值较为接近的时候,训练器的性能才最好。(这个我暂时没有找到理论支持,只能从实验上看出来)
- 如果两个阈值相距比较远,就是我们之前说的mismatch问题了。
- 单一阈值训练出的检测器效果非常有限,单一阈值不能对所有的Proposals都有很好的优化作用。
从而引出cascade rcnn结构:直观的理由很简单,就是综合各个iou阈值来进行训练,这样可以更好匹配训练集的iou阈值,提升精度。
1.3 cascade 结构
1.4 总结
RPN提出的proposals大部分质量不高,导致没办法直接使用高阈值的detector,Cascade R-CNN使用cascade回归作为一种重采样的机制,逐stage提高proposal的IoU值,从而使得前一个stage重新采样过的proposals能够适应下一个有更高阈值的stage。
- 每一个stage的detector都不会过拟合,都有足够满足阈值条件的样本。
- 更深层的detector也就可以优化更大阈值的proposals。
- 每个stage的H不相同,意味着可以适应多级的分布。
- 在inference时,虽然最开始RPN提出的proposals质量依然不高,但在每经过一个stage后质量都会提高,从而和有更高IoU阈值的detector之间不会有很严重的mismatch。
2. RPN
3. FPN
4. DCN
5. attention
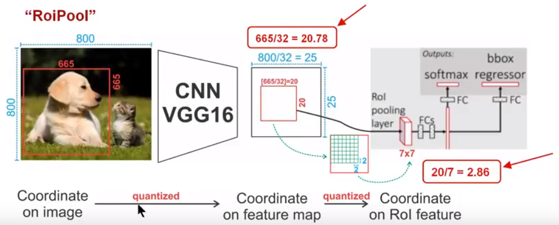
6. ROI
参照另一篇ROI的文章,也可以参考这篇文章
https://zhuanlan.zhihu.com/p/73138740
7. OHEM
8. warmup
在做一个数据量很大的训练(千万至亿级别),在一个epoch内,看到训练误差先减小后上升,然后通过观察测试集变化,排除了模型和数据出错的可能。最后把问题目标锁定在学习率过大,导致模型提前过拟合,结果对于新的训练数据loss变大。
warmup的实现:
if warmup: |
可以看到 warmup_lr 的初始值是跟训练预料的大小成反比的,也就是说训练预料越大,那么warmup_lr 初值越小,随后增长到我们预设的超参 initial_learning_rate相同的量级,再接下来又通过 decay_rates 逐步下降。
这样做有什么好处?
1)这样可以使得学习率可以适应不同的训练集合size,实验的时候经常需要先使用小的数据集训练验证模型,然后换大的数据集做生成环境模型训练。
2)即使不幸学习率设置得很大,那么也能通过warmup机制看到合适的学习率区间(即训练误差先降后升的关键位置附近),以便后续验证.
来源:https://www.zhihu.com/question/338066667/answer/973639422
参考
https://zhuanlan.zhihu.com/p/4255395 cascade rcnn
https://www.zhihu.com/question/338066667/answer/973639422 roi