协同过滤CF详解
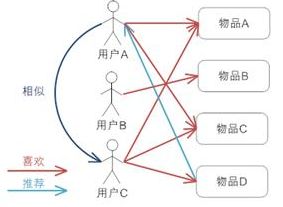
协同过滤CF详解1. user CF(uCF)一般步骤:
构建用户-物品矩阵,将用户表示为物品的向量;
计算向量的相似度;常用相似度为:
Jaccard相似系数
\begin{equation}
J(A,B) = \frac{A\cap B}{A\cup B}
\end{equation}
cosine相似系数
\begin{equation}
cos\theta = \frac{x_1x_2 + y_1y_2}{\sqrt{x_1^2 + y_1^2} \sqrt{x_2^2 + y_2^2}}
\end{equation}
皮尔逊相关系数
\begin{equation}
P(p,q) =\frac{\sum_{i=1}^{n}(p_i-\bar{p})(q_i-\bar{q})}{\sqrt{\sum_{i=1}^{n}(p_i-\bar{p})^2} \sqrt{\sum_{i=1}^{n}(q_i-\bar{q})^2}}
\end{equation}
欧式距离
找到与目标用户最相似的K个用户
通过这个K个人对目标用户-物品进行打分,排序后推荐,一般根据 ...
BN层详解
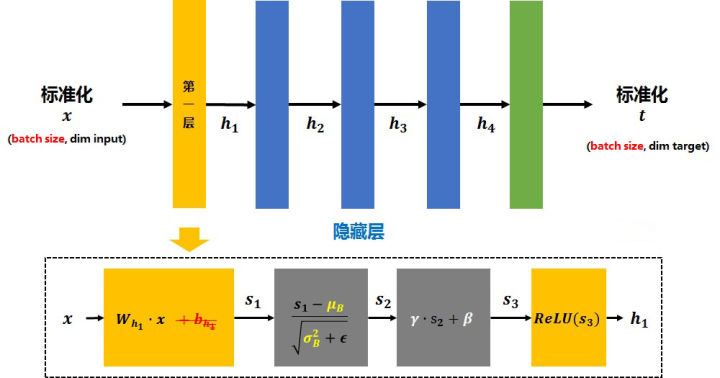
BN(batch normalization)详解1. 公式normalization过程
整个过程:batch均值 -> 方差 -> 标准化(正太化)-> 尺度和偏差变换 -> 训练过程更新$\gamma$和$\beta$
反向传播参数更新的方法:
2. 解决的问题解决问题:解决梯度消失和梯度爆炸问题,同时加快训练。
原理:以sigmoid为激活函数为例
当陷入两端之后,会造成梯度消失,BN将数据限制在0.5左右的线性区,解决了梯度消失的问题。同理,使用Relu激活函数,当正方向很大时,梯度爆炸,负方向时,梯度消失。
3. BN使用方法BN层一般用在conv层后,activation前
应用步骤:
训练的时候,是根据输入的每一批数据来计算均值和方差,测试的时候,输入平均值和方差是整体测试集的,每层BN的平均值和方差是训练时记录的滑动平均值
pytorch中具体记录和更新均值和方差参考:https://blog.csdn.net/ecnu_lzj/article/details/104203604
由此联想到dropout:假设drop_out的k ...
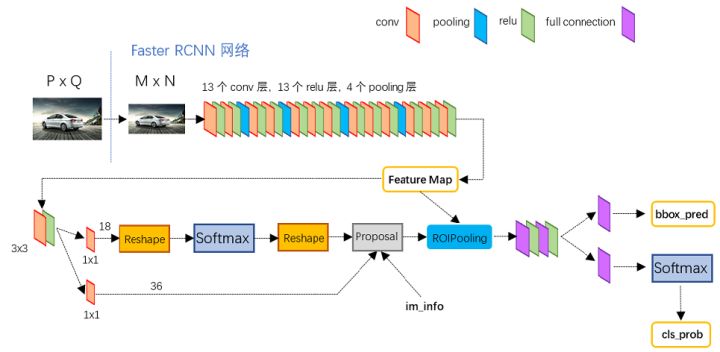
faster rcnn相关详解
faster rcnn相关详解1. cascade rcnn1.1 mismatch问题:在R-CNN中用到IoU阈值的有两个地方,分别是Training时Positive与Negative判定,和Inference时计算mAP。
training阶段,RPN网络提出了2000左右的proposals,这些proposals被送入到Fast R-CNN结构中,在Fast R-CNN结构中,首先计算每个proposal和gt之间的iou,通过人为的设定一个IoU阈值(通常为0.5),把这些Proposals分为正样本(前景)和负样本(背景),并对这些正负样本采样,使得他们之间的比例尽量满足(1:3,二者总数量通常为128),之后这些proposals(128个)被送入到Roi Pooling,最后进行类别分类和box回归。
inference阶段,RPN网络提出了300左右的proposals,这些proposals被送入到Fast R-CNN结构中,和training阶段不同的是,inference阶段没有办法对这些proposals采样(inference阶段肯定不知道gt的,也 ...
DSSM模型详解
DSSM模型详解1. DSSM模型原理和结构
模型原理:
通过搜索引擎里Query和Document的海量的点击曝光日志,用DNN深度网络把Query和Document表达为低维语义向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低维语义Embedding向量。
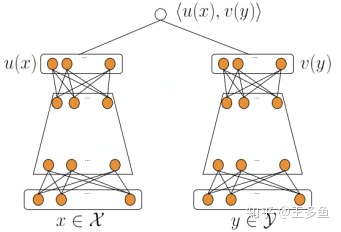
模型结构
其中Q代表Query信息,D表示Document信息。(1)Term Vector:表示文本的Embedding向量;(2)Word Hashing:为解决Term Vector太大问题,对bag-of-word向量降维;(3)Multi-layer nonlinear projection:表示深度学习网络的隐层;(4)Semantic feature :表示Query和Document 最终的Embedding向量;(5)Relevance measured by cosine similarity:表示计算Query与Document之间的余弦相似度(6)Posterior probability computed ...
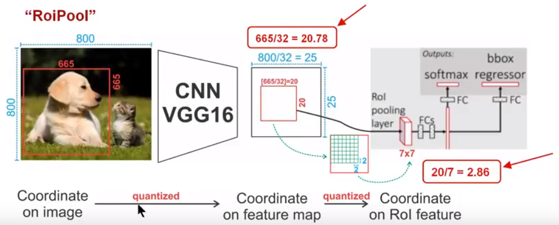
ROI详解
ROI详解1. ROI pooling在Faster RCNN中用以将rpn生成的候选框region proposal,映射为固定大小的feature map
工作原理为:
Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800*800,最后一层特征图feature map大小:25*25
假定原图中有一region proposal,大小为665*665,这样,映射到特征图中的大小:665/32=20.78,即20.78*20.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20*20
假定pooled_w=7,pooled_h=7,即pooling后固定成7*7大小的特征图,所以,将上面在 feature map上映射的20*20的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.86*2.86,此时,进行第二次量化,故小区域大小变成2*2
每个2*2的小 ...

多模态综述
1. multimodal 综述
2. 具体模型发展
LR推导
LR推导1. 简介分类任务与回归任务的区别:
输出变量为连续变量的预测问题——回归任务;
输出变量为有限个离散变量的预测问题——分类任务;
逻辑回归的本质是通过回归的方法来解决分类任务,即通过回归预测概率,进而得到分类结果。
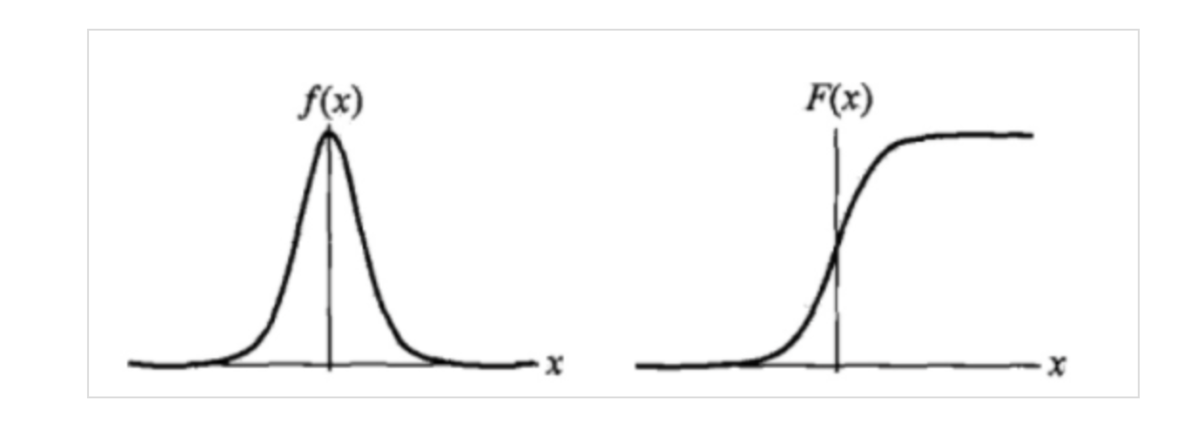
2. 相关概念几率:指一件事发生与不发生概率的比值。
对数几率:
\begin{equation}
logit(p) = log(\frac{p}{1-p})
\end{equation}逻辑斯谛分布:其分布函数为
\begin{equation}
F(X) = P(X \leq x) = \frac {1} {1 + e ^ {-(x - \mu)/\gamma}}
\end{equation}概率密度函数为
\begin{equation}
f(x) = F^{\prime}(x) = \frac {e^{-(x - \mu)/\gamma}}{\gamma {(1 + e^{-(x - \mu)/\gamma})}^2}
\end{equation}其中 $\mu$ 为位置参数,$\gamma > 0 $ 为形状参数,其以 $(\mu, \f ...

手写NMS&soft-NMS
手写NMS & soft-NMS1. NMS(非极大抑制)简介非极大抑制算法应用相当广泛,其主要目的是消除多余的框,找到最佳的物体检测位置。
其实现的思想主要是将各个框的置信度进行排序,然后选择其中置信度最高的框A,将其作为标准选择其他框,同时设置一个阈值,当其他框B与A的重合程度超过阈值就将B舍弃掉,然后在剩余的框中选择置信度最大的框,重复上述操作。
实现参考faster rcnn源码 lib/nms/py_cpu_nms.py
import numpy as npdef nms(dets, thresh): x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] score = dets[:, 4] areas = (x2 - x1 + 1) * (y2 - y1 + 1) keep = [] order = score.argsort()[::-1] # 按score从大到小得到索引排列 while order.size > 0: ...

ML/DP相关公式
一、loss function1、均方误差(MSE,L2损失)
MSE=\sum_{i=1} ^n (y_i - y_i ^p)^2
\frac{\partial MSE}{\partial y_i}=2\sum_{i=1} ^n (y_i - y_i ^p)回归问题中最常见的损失函数。如果对所有样本点只给出一个预测值,那么这个值就是所有目标值的平均值。
优点:计算简单,逻辑清晰,衡量误差准确;梯度随着误差的增大或减小,收敛效果好;
缺点:对于异常值敏感,会对其赋予较大的权重,如果异常值不属于考虑范围,则会造成偏差;
2、平均绝对值误差(又称MAE,L1损失)
MAE=\sum_{i=1} ^n |y_i - y_i ^p|
\frac{\partial MAE}{\partial y_i}=
\begin{cases}
1 && y_i > y_i ^p \\
-1 && y_i < y_i ^p
\end{cases}x 在 y_i=y_i ^p处不可导 ,如果对所有样本点只给出一个预测值,那么这个值就是所有目标值的中位数
优点:对于异常值有较好的鲁棒性;
缺点:梯度不 ...

Leetcode
二叉树1、前序遍历根 -> 左 -> 右
递归:root.val + func(root.left) + func(root.right)
迭代: [root] -> stack.pop -> root.right -> root.left
# Definition for a binary tree node.# class TreeNode:# def __init__(self, x):# self.val = x# self.left = None# self.right = Noneclass Solution: def __init__(self): self.res = [] def preorderTraversal(self, root: TreeNode) -> List[int]: # 1、递归 if not root: return self.res self.r ...