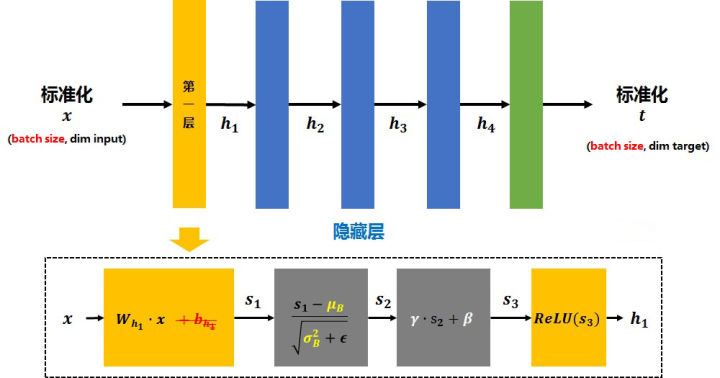
BN(batch normalization)详解
1. 公式
normalization过程

整个过程:batch均值 -> 方差 -> 标准化(正太化)-> 尺度和偏差变换 -> 训练过程更新$\gamma$和$\beta$
反向传播参数更新的方法:
2. 解决的问题
解决问题:解决梯度消失和梯度爆炸问题,同时加快训练。
原理:以sigmoid为激活函数为例
当陷入两端之后,会造成梯度消失,BN将数据限制在0.5左右的线性区,解决了梯度消失的问题。同理,使用Relu激活函数,当正方向很大时,梯度爆炸,负方向时,梯度消失。
3. BN使用方法
BN层一般用在conv层后,activation前
应用步骤:
训练的时候,是根据输入的每一批数据来计算均值和方差,测试的时候,输入平均值和方差是整体测试集的,每层BN的平均值和方差是训练时记录的滑动平均值
pytorch中具体记录和更新均值和方差参考:https://blog.csdn.net/ecnu_lzj/article/details/104203604
由此联想到dropout:假设drop_out的keep_prob为0.8,也就是80%概率保存神经元,1-80%概率丢掉神经元,那么测试的时候需要每个神经元乘以keep_prob。参考http://www.360doc.com/content/18/1203/22/54525756_799102767.shtml
4. 其他Nomalization方法:
问:为什么要做归一化处理?
答:神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。
BN、LN、IN和GN这四个归一化的计算流程几乎是一样的,可以分为四步:
计算出均值
计算出方差
归一化处理到均值为0,方差为1
变化重构,恢复出这一层网络所要学到的分布
Layer Normalizaiton:
LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响;
常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理;
Instance Normalization
IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响;
常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理;
Group Normalizatio
GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW;
GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C;
Switchable Normalization
- 将 BN、LN、IN 结合,赋予权重,让网络自己去学习归一化层应该使用什么方法;
- 集合上述方法,但训练复杂;
参考
https://blog.csdn.net/weixin_43937316/article/details/99573134
https://blog.csdn.net/u013289254/article/details/99690730 五种归一化方法
https://blog.csdn.net/ecnu_lzj/article/details/104203604 pytorch-BN
http://www.360doc.com/content/18/1203/22/54525756_799102767.shtml dropout