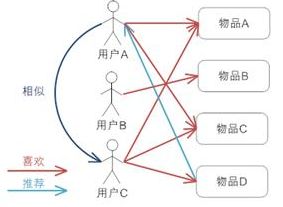
协同过滤CF详解
1. user CF(uCF)
一般步骤:
构建用户-物品矩阵,将用户表示为物品的向量;
计算向量的相似度;常用相似度为:
- Jaccard相似系数
cosine相似系数
皮尔逊相关系数
欧式距离
找到与目标用户最相似的K个用户
通过这个K个人对目标用户-物品进行打分,排序后推荐,一般根据相似度做加权平均,来计算目标用户对物品的偏好程度
2. item CF(iCF)
一般步骤:
同ucf,只是将用户-物品矩阵,转化为物品-用户矩阵
3. uCF和iCF优缺点比较
| UserCF | ItemCF | |
|---|---|---|
| 性能 | 适用于用户较少的场合,如果用户很多,计算用户相似度矩阵代价很大 | 适用于物品数明显小于用户数的场合,如果物品很多(网页),计算物品相似度矩阵代价很大 |
| 领域 | 时效性较强,用户个性化兴趣不太明显的领域 | 长尾物品丰富,用户个性化需求强烈的领域 |
| 实时性 | 用户有新行为,不一定造成推荐结果的立即变化 | 用户有新行为,一定会导致推荐结果的实时变化 |
| 冷启动 | 在新用户对很少的物品产生行为后,不能立即对他进行个性化推荐,因为用户相似度表是每隔一段时间离线计算的 | 新用户只要对一个物品产生行为,就可以给他推荐和该物品相关的其他物品 |
| 新物品上线后一段时间,一旦有用户对物品产生行为,就可以将新物品推荐给和对它产生行为的用户兴趣相似的其他用户 | 但没有办法在不离线更新物品相似度表的情况下将新物品推荐给用户 | |
| 推荐理由 | 很难提供令用户信服的推荐解释 | 利用用户的历史行为给用户做推荐解释,可以令用户比较信服 |
4. 矩阵分解
解决的关键问题:弥补协同过滤无法处理稀疏矩阵的问题。将高维稀疏矩阵映射为低维矩阵的乘积,用稠密隐向量表示user和item,挖掘用户和物品的隐含特征和关系。
矩阵分解算法详细过程:假设用户-物品矩阵大小为m*n,则将其分解为m*k的用户矩阵和k*n的物品矩阵。m为用户数量,n为物品数量,k为隐向量的维度,决定了隐向量的表达能力强弱,k越小,泛化能力越强,但含有信息越少,k越大表达能力越强,泛化则降低。
用户i对物品i的评分则为:
其中 $p_u$ 为用户u在用户矩阵的行向量,$q_i$ 为物品i在物品矩阵的列向量
SVD要求矩阵是稠密的,不能有缺失值,所以不能直接应用于推荐,所以发展而来的应用于推荐的方法有funkSVD,biasSVD,SVD++等
其中funkSVD的采用的思想就是拟合用户-物品矩阵,线性回归的思想,通过均方差误差反向传播来计算$p_u$和$q_i$
参考
https://blog.csdn.net/sunkun2013/article/details/71196884
https://blog.csdn.net/u012151283/article/details/77716085
https://zhuanlan.zhihu.com/p/183860866
https://www.cnblogs.com/pinard/p/6351319.html 多种SVD分解
https://blog.csdn.net/qq_38415758/article/details/109528427 MF